Software skärmdump:
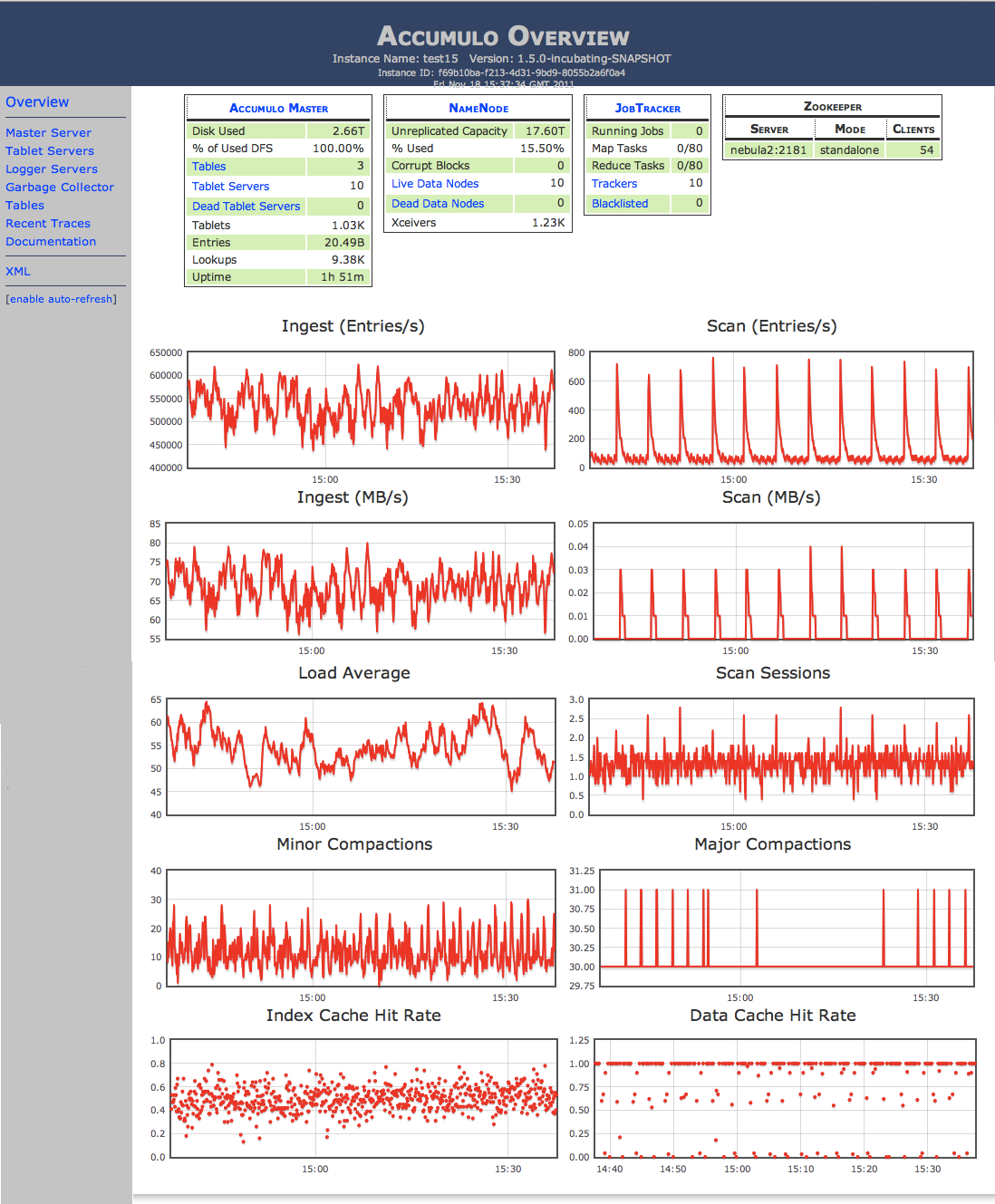
Mjukvaruinformation:
Version: 1.7.0 Uppdaterad
Ladda upp dagen: 4 Jun 15
Utvecklare: Apache Software Foundation
Licens: Gratis
Popularitet: 151
Apache Accumulo är en mashup av olika tekniker, från Googles Bigtable , till Apache Hadoop , Thrift och Zookeeper .
Jämfört med Googles Bigtable system Accumulo har några förbättringar av sina egna.
Dessa inkluderar bords cellbaserade åtkomstrestriktioner, en server-side-system för hantering av nyckel-värde-par vid önskade tidpunkter och under optimala förhållanden, och massor av klient API.
Databasen är verkligen inte för att köra dina dagliga webbplatser och inriktning för cloud computing miljöer där utvecklare måste hantera humongous mängder information
Vad är nytt i den här versionen.:
- Användning av Hadoop CredentialProviders
- Skriv-Ahead Logga synk prestanda
- Mindre-kompaktorer inte aggressiv nog
- genomförandet Skriv-Ahead log sync
- HeapIterator optimering
Vad är nytt i version 1.6.2:
- Användning av Hadoop CredentialProviders
- Skriv-Ahead Logga synk prestanda
- Mindre-kompaktorer inte aggressiv nog
- genomförandet Skriv-Ahead log sync
- HeapIterator optimering
Vad är nytt i version 1.6.0:
- Service IP-adresser
- Flera volym stöd
- Tabellnamn
- Pluggbar packningsstrategier
- Villkorliga mutationer
- Plats grupper i minnet
- Storlek baserade hinder för nya tabeller
Vad är nytt i version 1.4.1:.
- Alternativt övervaka swappiness på varje server
- Support körs på toppen av Kerberos-aktiverade HDFS.
- Ange metod för att samla in systemet statistik API.
Vad är nytt i version 1.4.0:
- Tablet sammanslagning
- Effektiv borttagning av raden intervall
- Komprimering av raden intervall
- Tabell kloning
- FATE: feltolerant Executor. Används för att göra tabellen drift överleva mästare omstart.
- Samtidig bord drift utföra korrekt
- Bulk belastning nu görs av huvud- och tablett servrar och använder öde att överleva servern startar.
- Multi-level RFIL index
- Sammanfoga små kompaktorer
- Logisk tid för bulk import
Kommentarer hittades inte