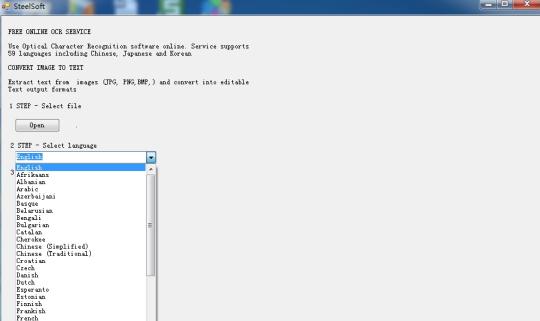
Tolka text från bilder med Tesseract OCR Engine bygger på moln teknik.
Använda programvara Optical Character Recognition nätet. Tjänsten stöder 59 språk inklusive kinesiska, japanska och koreanska. Extrahera text från bilder (JPG, PNG, BMP, TIF) och konvertera till redigerbar text utdataformat.
Den bygger på moln teknik, och mycket berömda OCR-motorn (Tesseract OCR Engine), så det finns bara hundratals KB i storlek, men det kan extrahera text på 59 språk, från bilderna.
Den har stöd för fler språk: bulgariska, katalanska, tjeckiska, danska, holländska, engelska, finska, franska, tyska, grekiska, ungerska, indonesiska, italienska, lettiska, litauiska, norska, polska, portugisiska, rumänska, ryska, serbiska, slovakiska, slovenska , spanska, svenska, tagalog, turkiska, ukrainska, vietnamesiska etc
Vad är nytt i den här versionen:..
Version 5.0 innehåller UE förbättringar
Kommentarer hittades inte