
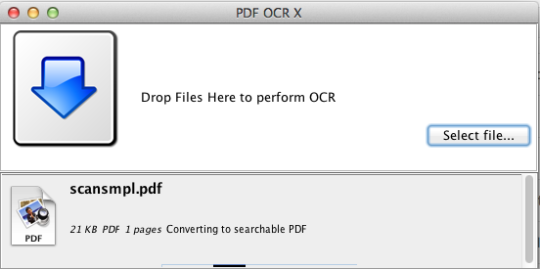
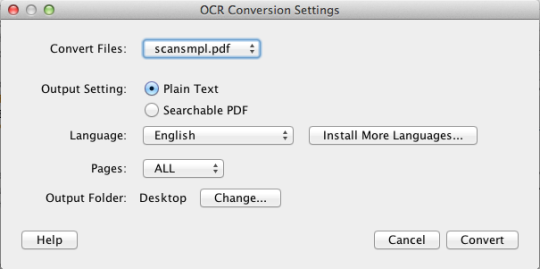
PDF OCR X är ett enkelt drag-och-släppverktyg för Mac OS X, som omvandlar dina PDF-filer och bilder till text eller sökbara PDF-dokument. Den använder avancerad teknik för OCR (optisk teckenigenkänning) för att extrahera texten i PDF-filen (eller bilden) även om den texten finns i en bild. Detta är särskilt användbart för hantering av PDF-filer och bilder som skapades via en Scan-to-PDF-funktion i en skanner eller fotokopierare. Stödjer över 60 språk för OCR. OCR-motorn är baserad på Tesseract. Gemenskapsversionen stöder enkelsidiga PDF-filer (eller den första sidan av flersidiga PDF-filer). För flera sidors PDF-stöd bör du uppgradera till Enterprise Edition.
Vad är nytt i den här utgåvan:
Version 2.1.1 lägger till stöd för Mojave , och förbättrar användargränssnittet på näthinnan.
Vad är nytt i version 2.0.8:
Fixerat problem med hantering av vissa PDF-filer med rotation.
Begränsningar :
Gemenskapsutgåvan är begränsad till PDF-filer och bilder på en enda sida.


Kommentarer hittades inte