uni2ascii och ascii2uni konvertera mellan UTF-8 Unicode och något av en mängd av 7-bitars ASCII-motsvarigheter inklusive: hexadecimal och decimal HTML numeriska teckenreferenser, u-rymningar, standard hexadecimal och rå hexadecimal.
Sådana ASCII medel är användbara när inklusive Unicode-text i programkälla, när du skriver text i webbprogram som kan hantera Unicode-teckenuppsättningen, men inte 8-bitars säker, och när felsökning.
Unicode flyr finns är:
- HTML hexadecimala numeriska teckenreferenser (t ex)
- HTML decimal numeriska teckenreferenser (t.ex. ȳ)
- U-rymning, såsom det används i Python (t ex u00E9)
- U-rymningar inom BMP och U-rymningar utanför BMP, t.ex. u00E9 men U00010024.
- U -escapes (t ex U 00E9)
- U-escapes (t ex U00E9)
- U-escapes (t ex u00E9)
- U-rymningar inom vinkelfästen (t.ex.)
- X-escapes (t ex x00E9)
- X-rymningar med hängslen (t ex x {00E9})
- Standard hexadecimal (t.ex. 0x00E9)
- Rå hexadecimal (t.ex. 00E9)
uni2ascii accepterar en kommandorad flagga avgöra om att generera versaler AF eller gemena af som hexadecimala siffror eftersom vissa vissa program accepterar endast det ena eller det andra. ascii2uni accepterar heller.
När det gäller uni2ascii som standard, är bara tecken utanför ASCII-intervallet konverteras. Även om ASCII-tecken är också omvandlas är radbrytningar bevaras om konvertering uttryckligen begärt. Rymd tecken bevaras också om omvandling uttryckligen begärt. I fallet med de tre icke-ASCII-tecken utrymme (etiopiska ord utrymme, Ogham utrymme, och ideografiska utrymme), om utrymmet tecken som inte konverteras, dessa ersätts med ASCII utrymme (0x20) för att hålla produktionen inom 7- bitars ASCII-intervallet.
Detta paket innehåller fyra program. Huvudprogrammet är uni2ascii. Det är skrivet i C och måste kompileras. uni2html.py är föregångaren till uni2ascii. Som det står skrivet i Python, behöver det inte att sammanställas och bör köras på nästan alla aktuella datorn. uni2ascii är annars överlägsen av att:
- Den genererar en bredare utformat.
- Det är ungefär 20 gånger snabbare.
- Den hanterar ingång i hela 32 bitars Unicode sortiment. Däremot hanterar endast den uni2html
Basic Multilingual Plane (Plane 0) eftersom det för närvarande Python representerar Unicode kodad text internt med hjälp av 16-bitars heltal. Om du har text i, säg, Linear B eller Ugaritiska behöver du uni2ascii.
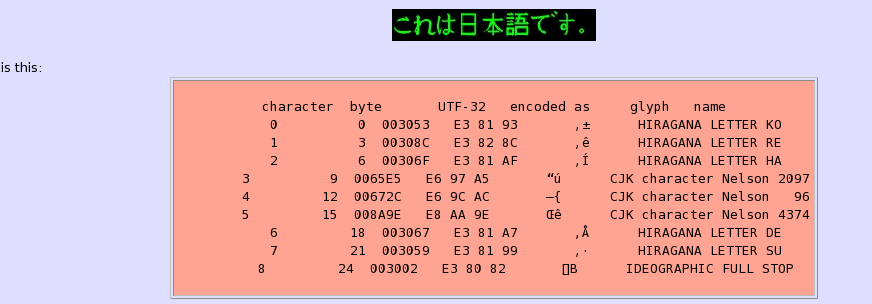
Det gör ett bättre jobb med att rapportera fel. Om det påträffar ett fel i sin ingång, såsom mal-formad UTF-8, rapporterar den platsen för felet både i termer av antal tecken från början av filen (med början vid 0) och i termer av antal byte från början av filen (också börjar vid 0). (Character räknas och byte räknas i allmänhet inte samma sak eftersom en UTF-8-kodad tecken upptar en till fyra byte.) Endast Python versionen rapporternas karaktär räknas. uni2ascii ger också information om vilken typ av fel.
Det tredje programmet, ascii2uni, är inversen av uni2ascii. Det accepterar text som innehåller en mängd olika ASCII representationer av Unicode-tecken och genererar UTF-8 Unicode.
Det fjärde programmet, ascii2uni.py läser 7-bitars ASCII innehållande u-flydde Unicode, som användes i Python och Tcl, och omvandlar den till UTF-8 Unicode. Det är det ursprungliga programmet som ascii2uni är en generalisering
Vad är nytt i den här versionen.
- Fixat bugg i uni2ascii i vilken i vissa fall subsitution räkna var för hög, fastställande Debians felrapport # 626.268.
- Patched att hantera situationen i NetBSD som saknar getline.
- klarade semantik ren alternativ som konverterar tecken i ASCII intervall annat än utrymme och nyrad. Fixat bugg där detta inte ett korrekt sätt för UTF8 typer.
Vad är nytt i version 4.17:
- Till uni2ascii följande omvandlingar till närmaste ascii motsvarande: U 2022 kula till "o", U + 00B7 mitten prick till perioden, U + 0085 nästa rad att newline, U + 2028 linje separator till nyrad.
Vad är nytt i version 4.16:
- Q-formatet fungerar igen i ascii2uni .
- Lade U + 2033 DOUBLE PRIME till karaktärerna omvandlas till deras närmaste ascii motsvarande under användning av e-formatet i uni2ascii.
Vad är nytt i version 4.15:
- Omdöpt endian.h att u2a_endian.h att eliminera konflikt med extern endian.h.
- Bort kopia av GNU getline från ascii2uni.c eftersom det är standard från och med POSIX2008.
Vad är nytt i version 4.14:
- Fixat en bugg som störde med användning av Q-format i uni2ascii.
- Fixat bugg där ascification U + 2502 och U + 2503 lagt dubbla citattecken för att mata ut.
- Fixat en bugg där -a S alternativet genereras en & quot; Omräknat så många tecken & quot; linje för varje tecken på grund av att de lämnar i felsökning av kod.
Vad är nytt i version 4.13:
- Fixat bugg som orsakade alltför många tecken ändras till ASCII till rapporteras.
Vad är nytt i version 4.12:
- Båda programmen nu tillåta ingångs filnamnet som ska anges på kommandoraden utan omdirigering.
Vad är nytt i version 4.11:
- lägger här versionen stöd för & lt; XX & gt; & lt; XX & gt; och% uXXXX format.
Vad är nytt i version 4.10:
- Denna utgåva rättar en bugg som gjorde Y argument till -En flagg ascii2uni en no-op, och korrigerar manualsidorna och hjälp för Y och Q argument -a flagga för båda programmen.
- Y argument är nu ett fel för uni2ascii.
- versionsinformationen och action sammanfattningar är mer informativ.
Kommentarer hittades inte