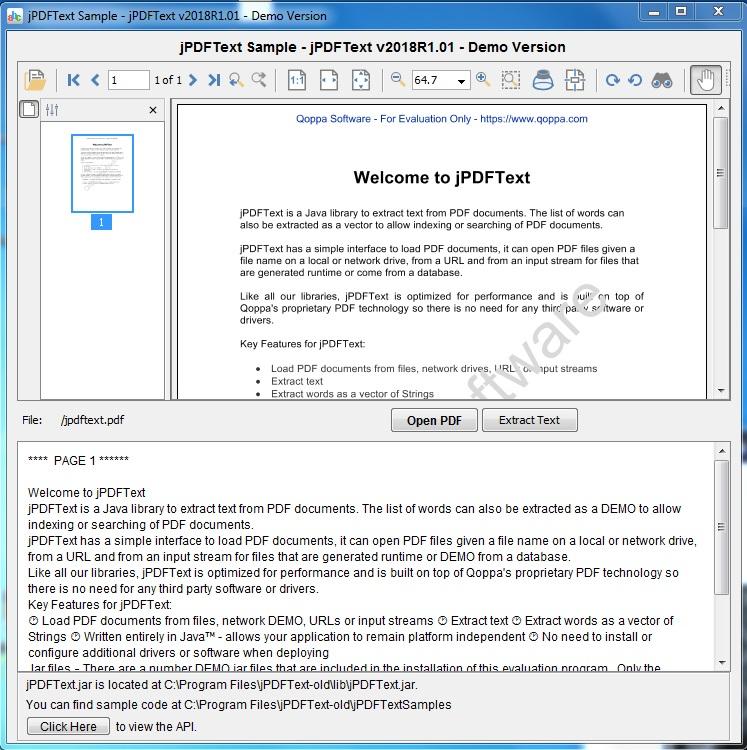
jPDFText är ett Java-bibliotek för att extrahera text från PDF-dokument. Med jPDFText kan PDF-dokument bearbetas för att extrahera textinnehållet för arkivering, lagring, sökning eller indexering. jPDFText bygger på Qoppas proprietära PDF-teknik så att du inte behöver installera någon tredje parts programvara eller drivrutiner. Eftersom det är skrivet i Java tillåter det att din applikation är plattformsoberoende och körs på Windows, Linux, Unix (Solaris, HP UX, IBM AIX), Mac OS X och någon annan plattform som stöder Java runtime-miljön.
Viktigaste egenskaper:
Ladda PDF-dokument från filer, nätverksstationer, webbadresser eller inmatningsflöden.
Extrahera text i den logiska läsordningen.
Extrahera ord som en vektor av strängar.
Fungerar på Windows, Linux, Unix och Mac OS X (100% Java).
Du behöver inte installera eller konfigurera ytterligare drivrutiner eller programvara när du installerar.
Testad på JDK 1.4.2 och senare.

Kommentarer hittades inte