Gratis OCR-program för att extrahera text från bildfiler och PDF poster. Ett grafiskt användargränssnitt (GUI) för Tesseract OCR-motor.
Ansökan är enkel att installera och, ännu viktigare, gratis att använda, öppen källkod och 100% adware och spyware fri.
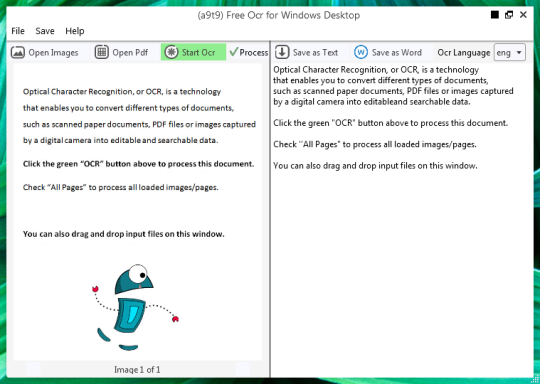
Du kan öppna en bild eller PDF-fil. Innehållet i källfilen visas i det vänstra fönstret. Om dokumentet som mer än en sida, eller om du öppnade flersidiga dokument, använd pilarna längst ner för att växla mellan dem,
Du startar OCR genom att klicka på den gröna knappen OCR, och du kommer att se resultatet i den andra högra fönstret. Utgångs text kan sparas som en textfil eller Word-dokument.
Tyvärr omvandlingen kvaliteten är inte så stor. Bakom scenen den använder Tesseract öppen källkod OCR-motor. Kvaliteten varierar från språk till språk -. Så gå vidare och testa om det är tillräckligt för dina behov
För mjukvaruutvecklare och nördar: The Free OCR för Windows Desktop verktyg är i grunden ett grafiskt användargränssnitt front-end (GUI) för Tesseract OCR-motorn. Den fullständiga källkoden finns tillgänglig (GPL-licens).
OCR-motorn av programvaran stöder följande OCR-språk: engelska, franska, italienska, tyska, spanska, brasiliansk portugisiska och holländska. Från och med version 3 den kan känna igen arabiska, bulgariska, katalanska, kinesiska (förenklad och traditionell), kroatiska, tjeckiska, danska, holländska, engelska, tyska (standard och Fraktur manus), grekiska, finska, franska, hebreiska, hindi, ungerska, Indonesiskt, italienska, japanska, koreanska, lettiska, litauiska, norska, polska, portugisiska, rumänska, ryska, serbiska, slovakiska (standard och Fraktur manus), slovenska, spanska, svenska, tagalog, tamil, thailändska, turkiska, ukrainska och vietnamesiska.

Kommentarer hittades inte